《社群耳朵聽聽看》社群交流筆記|說服其實沒有用?

由於 Data Team 的交付產物有其特殊性:不是軟體本身,而是可用的資料。對於相關合作團隊而言,資料品質 (data quality) 才是最被在意的。但以 Data Engineer 的角度而言,除了資料品質外,包含程式碼品質、伺服器穩定、查詢效能、低延滯等軟體工程師在乎的價值,我們也都同等在乎。
不過,由於 Data Team 的交付產物有其特殊性,對於相關合作團隊而言,資料品質 (data quality) 才是最被在意的。當「我們在意的」和「別人以為我們該在意的」認知出現落差時,就為合作埋下了潛在未爆彈。
來自 Airbnb 的體悟
這次在 dbt 社群活動上有幸聽到來自 Airbnb 的工程師 Robert Chang 分享《Airbnb’s Journey Towards Data Quality》主題,最令人印象的橋段是,他們在 2019 年時面臨了整個資料體系越來越難以維護的困境,包括
- 指標的不一致性:相近指標散落在各處,只差一些篩選條件
- 資料管線的斷點:資料上游出錯時修正有侷限性,下游得自行處理
隨著產品資料量的提升及時間累積下來的各種問題,就像軟體工程常談的技術債一樣,資料工程的技術債堆積久了,就變成資料破產 (data bankrupt), Data Team 無法確保資料的準確性,問題盤查的速度也越來越緩慢。
這場演講真的非常讓人有共感,於是我也把握了 Q&A 時間提問:
『當 Data Team 希望有更多心力在工程基礎上扎根重構時,如何說服其他人理解我們正在做的事是為長遠計劃而努力,並化解對於過程中成本提升的不諒解?』
Robert 整個回應很精彩,不過這篇就不用逐字稿呈現,而是用我自己的體悟和經驗綜合起來分段講述。但有一句話實在太令人印象深刻,深刻到成為這篇文的標題,而且一定要原汁原味描述給各位讀者聽:
『說服其實沒有用。』
重構是必然的過程
重構真的難以避免,原因是在 Day 0 時我們無法完全確定產品日後的發展,自然也就很難確定要設計地多嚴謹/彈性,過猶不及。一個對於發展初期好上手的程式架構,可能隨著時間漸漸變得不合用或難以維護了。
以 data pipeline 而言,初期或許只需要簡單的 ELT 流程把資料從產品資料庫 (production database) 抓進資料倉儲就行了,開始有了 BI 需求後,各式各樣的 transformation scripts 應運而生。上面提到的資料破產問題在辦公室就演變成這樣的對話:
指標定義混亂
其他人:『finance 和 sales 的 dashboard 上怎麼 revenue 數字不一樣?資料不都來自 data team 嗎?』
Data Engineer:『兩個 team 提供的定義本來就不一樣,數字當然不一樣…』
程式架構混亂
Data Engineer:『pipeline 因為不預期資料 fail 了,我修改好了,有哪些相依部分要重新執行?』
也是 Data Engineer:(打開 VSCode,看到幾百個平攤出來的 transformation scripts)『算了,把出錯的部分改好就好。然後到 Slack 發個訊息通知一下相關 stack-holders 請他們留意並配合自行修改。』
『v1 就是寫來重構成 v2 的。』嗯,此言不虛。
但是,資料工程的重構跟應用程式的重構可不一樣呀,data warehouse 為了新架構所增加的 storage 要花錢,data pipeline 的每個 query 也都是 $$。data 架構的 v1 要重構成 v2 的成本包含人力、儲存費還有查詢費相當可觀,並行期間還要同時維護兩套系統。隨著時間推進,v1 會越來越難用,排解問題的速度也越來越慢,花的心力越來越多,還會壓縮到開發 v2 的量能。
其他人:『Data Team 怎麼都在花錢?開發 v2 對我們有什麼好處嗎?』
聽到這句,資料團隊在提案重構的討論現場直接崩潰,不給我們時間重構,接下來會越來越難維護了。
端出你的牛肉
重構當然有好處,v2 的資料架構讓工程師未來擴充功能或維護時,開發或錯誤修復的速度會加快。各部門取用資料時,定義更清楚一致,資料品質也會提升。
其他人:『重構計畫預計要多久?』
看來資料品質提升對其他人很有感,慢慢消除疑慮,並開始往時程評估的環節進行了!
Data Engineer:『從開始動工到完成驗證及搬遷要一年。』
其他人:『… 那可能不能做了,要再評估看看…』
資料架構重構跟應用程式改版不一樣,不只軟體層要改動,資料還要驗證、搬遷。但一年真的太久了,直接嚇跑大家。
一步一步來
不要太貪心,把一年的工程拆幾個階段 (phase),一次改動一個部分,分批修改、驗證及搬遷。這種方法的優勢在於,它可以減少大規模改變的風險。透過逐階完成的方式,data team 可以更容易地掌握潛在的問題,並及時進行修復,從而提高整體效率。
成本雖然少不了,每隔一段時間就要其他人對資料架構的效益有感。
如何「談」的順利?
提出明確的改善效益,並制定可行的分階段執行計畫,其實只是說服過程的一環。更重要的是發動者要找對人,事情才能成。
例如工程師發起重構規劃,尋求 PM 站在產品推進的角度認可,或是找有話語權的中高階主管、CTO 從工程職能角度同理。找到本身對資料/資料工程/資料架構具有相應專業經驗或素養的夥伴,能夠理解問題並認同計畫,對計劃的推進相當關鍵且重要。
Next Step
這是我當天的第二個問題:
『Data Team 的產出作為資料使用平台,如何兼容各部門的需求?』
講者的回應很簡要,能夠在 Data Team 的守備範圍(如:data collection/ingestion/transformation)大部分兼容是最好的,我們可以用工程的手法控管,掌握資料歷程 (data lineage) 也確保指標定義的一致性及資料品質。但仍有少部分必須放手,讓取用資料的部門自行處理。掌握 80–20 法則就行了。
結語|Takeaway
這天在 dbt 的社群活動上和許多資料科學從業者交流地十分暢快!很多經驗真的是需要一些工作歷練才能感同身受。
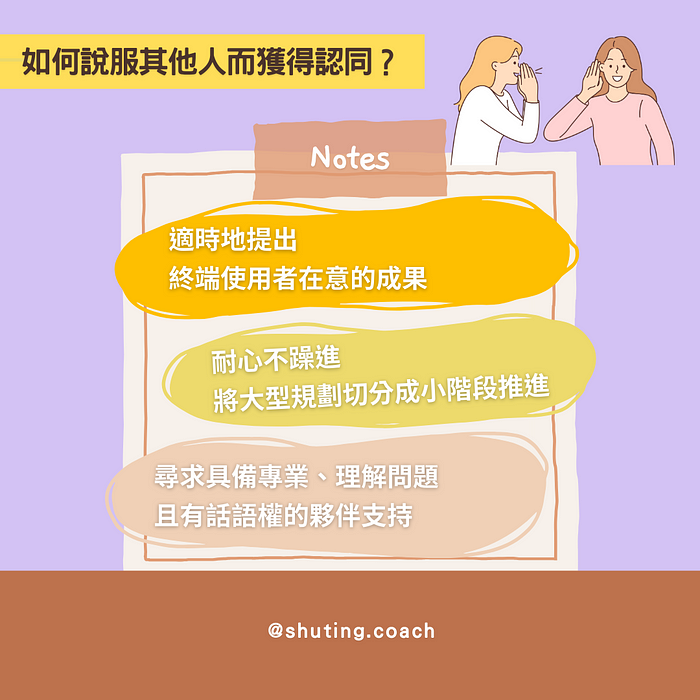
回到主題「說服其實沒有用?」當然不是說不需要去說服,而是指-應該換位思考,從對方最在意的點切入協調,才能慢慢獲得認同。以下是我的彙整:
- 適時提出終端使用者在意的成果:例如資料品質,不再一個 revenue 各自表述了。錯誤排除效率提升,以後大家自然不會覺得 Data Team 回應問題的速度緩慢了。
- 耐心不躁進,小步小步穩定前進:把大型規劃拆成小階段,每隔一段時間就推出一些成果,持續維持有感程度。
- 找到具有話語權的專業夥伴支持:尋求理解問題本質的夥伴支持,讓專業問題能夠專業解決。